疫情期间肯定有很多小伙伴需要上网课,但是有些网课我们感觉十分的鸡肋,自己不感兴趣,又必须要学
所以我写了这个刷网课的小程序,一方面是锻炼自己的爬虫技术,另一方面也给同学们节约宝贵的时间
几点说明:
1.此程序只供学习交流,请勿用于商业用途
2.当前只支持“兴趣课”的刷课,其他类型的课程还不支持
3.程序尚不完善,但是原理相通,举一反三,欢迎交流
如果你想要刷课服务,请找这个平台,快速刷课,还便宜:http://dao.cqrzr.com/
!
0x01 环境准备
python3.7+requests库+selenium库+火狐浏览器
python3.7和requests库的安装不必赘述 下面来讲一下selenium库,这也是我之一次用这个库,记录一下
因为目标网站是经过js渲染的,不使用selenium库很难抓取想要的数据,selenium库可以模拟浏览器进行 *** 作,同时可以配合各大主流浏览器,十分好用
安装:
官网:http://www.seleniumhq.org
中文文档:http://selenium-python-zh.readthedocs.io
selenium可以配合Phantom *** 一起使用,Phantom *** 可以创建无界面浏览器,使用起来要比浏览器高效,但是这回还是先从简单的用起来吧,而且调试还是很需要界面的
对于不同的浏览器,需要安装不同的驱动:
Chrome的驱动chromedriver 下载地址:http://chromedriver.storage.googleapis.com/index.html
Firefox的驱动geckodriver 下载地址:https://github.com/mozilla/geckodriver/releases/
IE的驱动IEdriver 下载地址:https://www.nuget.org/packages/Selenium.WebDriver.IEDriver/
我使用的是火狐浏览器,所以直接下载Firefox的驱动:
下载解压后,将geckodriver.exe添加到python的根目录下,其他浏览器也是一样,添加到python根目录下即可
0x02 核心原理
现在环境已经准备好了,开始研究刷课的原理
根据Firefox抓包可以发现:
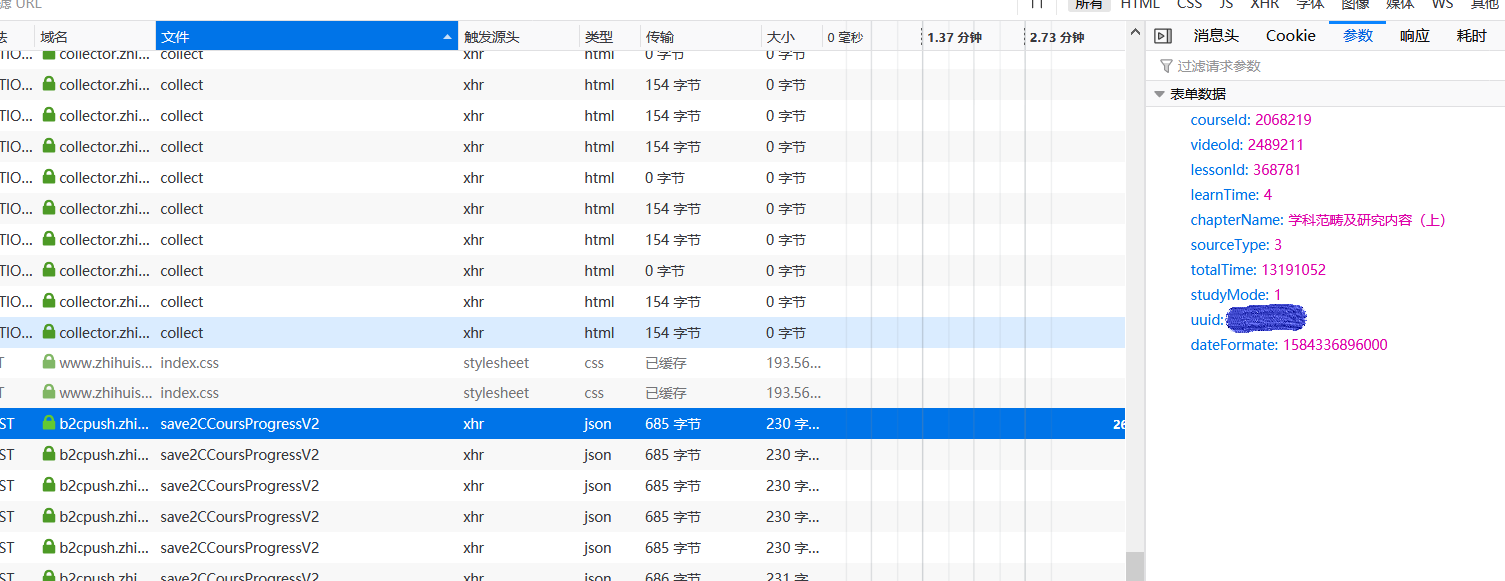
经过实验,我发现当每次用户离开当前界面(例如播放下一个视频、关闭网页)的时候,js都会向服务器发送一个名为save2CCoursProgressV2的post请求,这个包的参数是这样的:
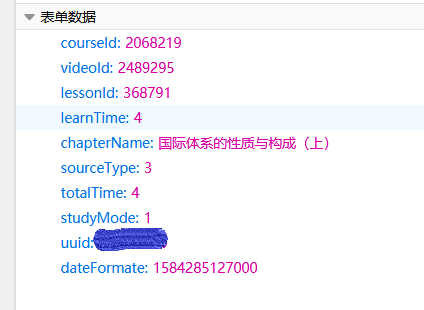
这些参数直接看名字就能知道是什么含义,最重要的参数就是learnTime和totalTime,应该是你观看视频的时间和待在当前界面的时间

所以只要我们构造这个save2CCoursProgressV2包,然后把相关的参数都填好,把learnTime和totalTime设置为一个很大的数,这样服务器就会认为你学习了很长很长时间
而且参数里面的uuid直接标注了用户的id,所以发这个包的时候甚至不需要cookie来认证,直接post就好了
但是需要注意的是,我们从哪里获取videoid和lessonid呢?如果id不对的话也是无法记录时间的
经过查找我发现,videoid并不是静态的存在网页中,js只会解析出当前播放的视频的videoid,这一点我会在后面的实现过程中详细说明
所以我们的工作还包括一个收集videoid和lessonid的过程
这就是本程序的核心原理,直接构造统计视频观看时长的数据包(其中相关参数需要收集),发送到服务器,从而避免浪费大量的时间来观看视频
0x03 实现过程
了解了实现的原理,就只差实现过程了
首先要初始化一个firefox浏览器:
尝试进入智慧树的学生主页:
发现要模拟登陆,不过幸运的是,智慧树登陆不需要验证码,可以直接用selenium进行登陆,否则的话就需要拿到cookie再发送请求了:
没有验证码,这一步就很简单,用selenium把用户名和密码填上,然后模拟浏览器去点击登陆按钮即可
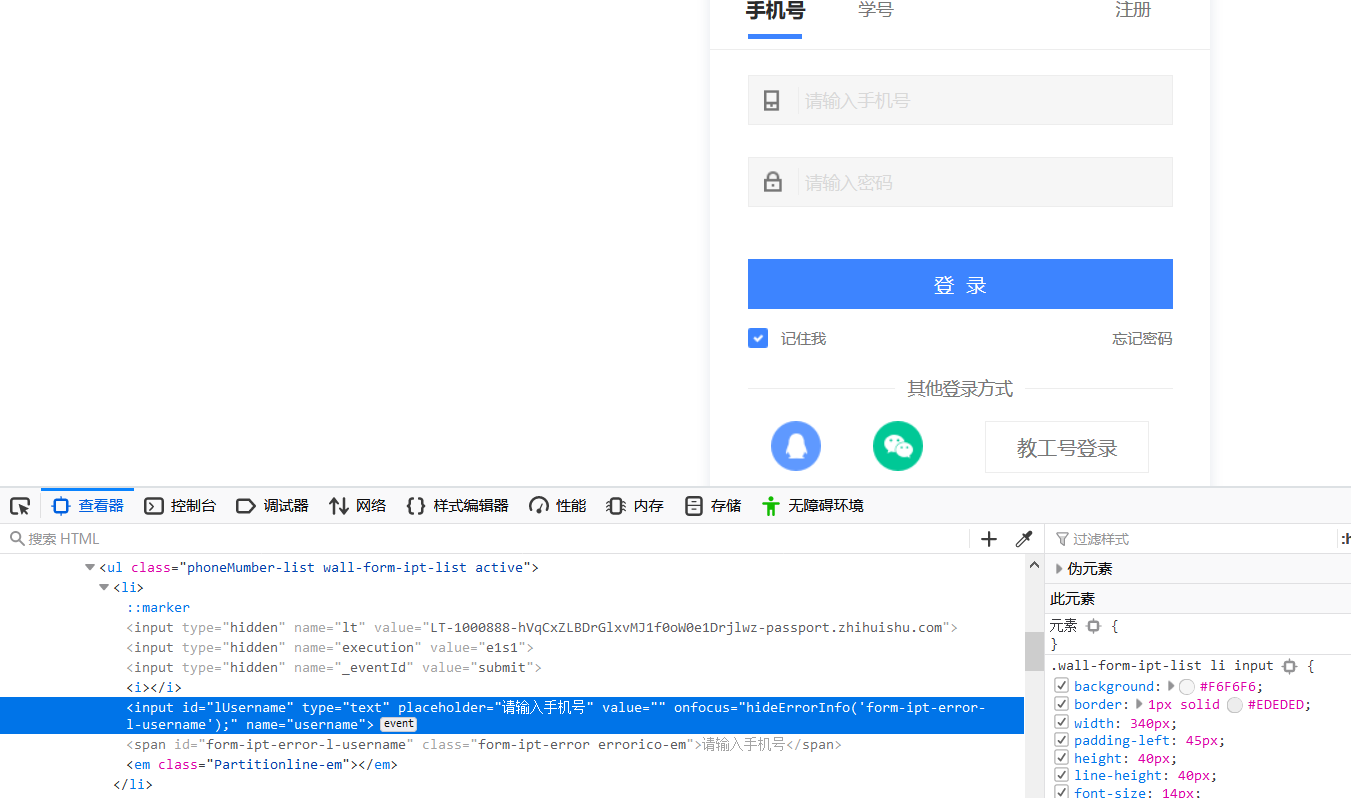
可以看到输入用户名这里,有一个id属性,值是 lUsername ,所以可以直接通过id定位用户名输入框,同理密码也是一样:
登陆按钮:

可以看到按钮的class属性为 wall-sub-btn 所以也可以直接定位 然后模拟点击:
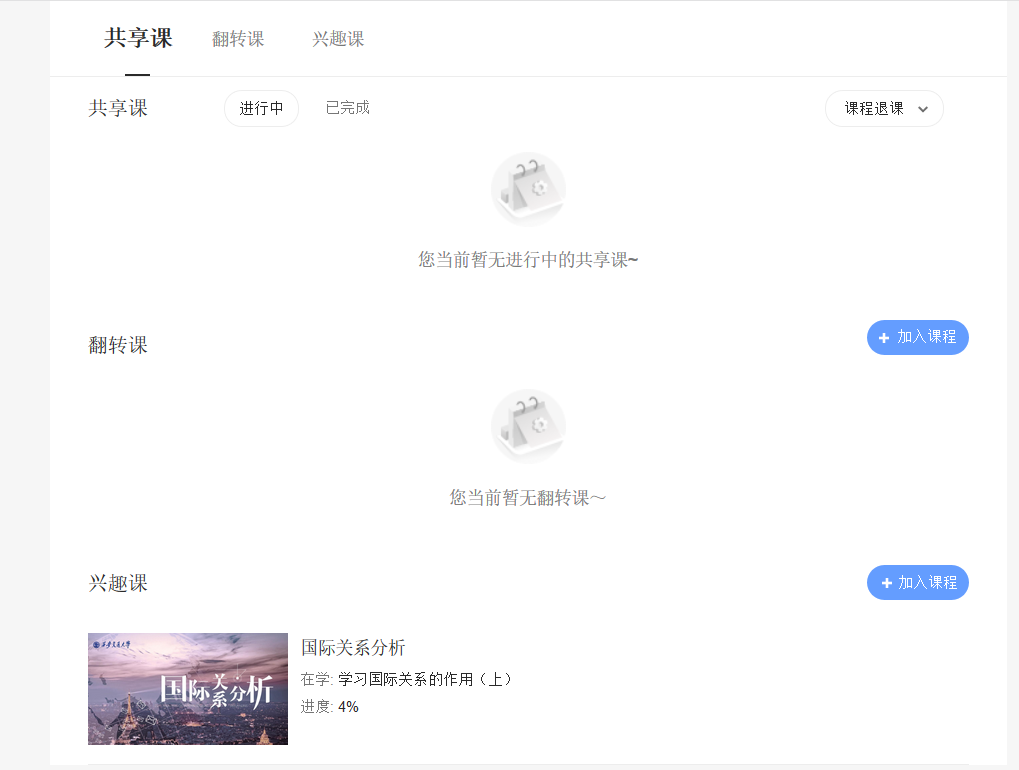
做到这一步就可以直接进入学生主页了,可以看到自己选修的课程:
下一步就是点开我要上的课:
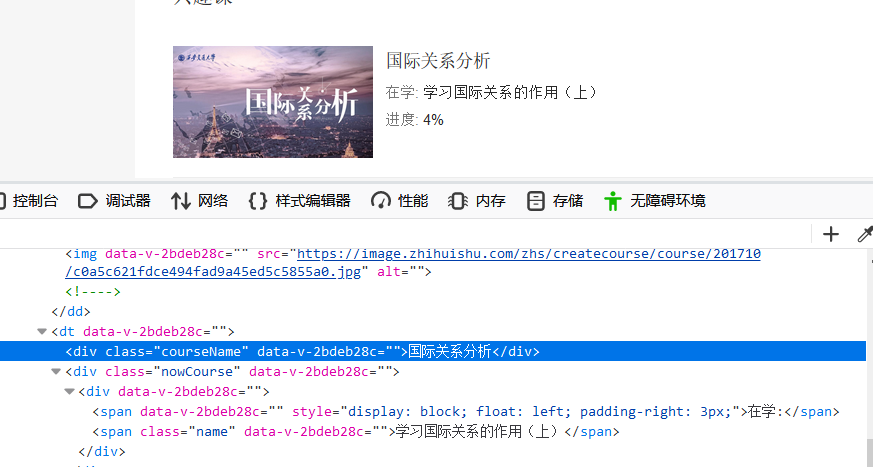
可以看到class属性值为 courseName 直接模拟点击就可以了:
但是需要注意的是,在这个语句之前,需要加上一个等待时间,必须等到网页加载完成了之后才能点击,否则有可能根本就找不到这个按钮
等待的 *** 有很多种,我直接用了最简单暴力的sleep(因为其他的 *** 不会...)
等待五秒钟后再点击就好了,不过要是实在网速不行,5秒也是有可能失败的....
之后就会出现一个弹窗:
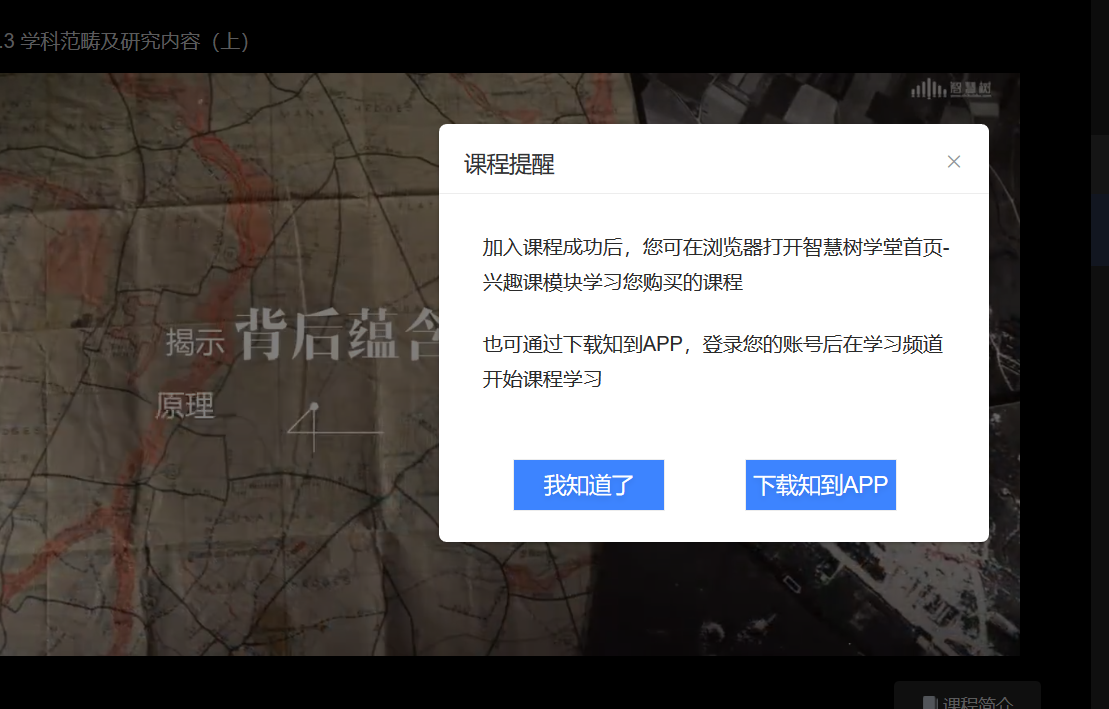
这里必须要把它点掉,也是和之前模拟点击按钮一样的 *** 作
点击完之后,就可以搜集我们想要的东西了(这里更好也加个sleep,给浏览器一点反应的时间)
首先是videoid,videoid怎么找呢?直接ctrl+F:
就可以定位到当前视频的videoid了,但是这个路径用之前找id属性或者class属性的话不是很好找,所以使用css选择器的 *** find_element_by_css_selector 定位到这里,
然后再用get_attribute *** 得到dataid的值,也就是videoid
复制css选择器:
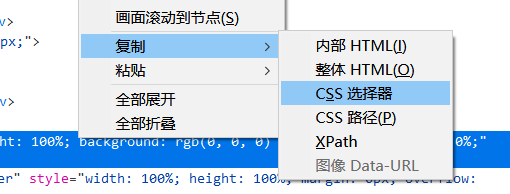
可以得到:.video-box > div:nth-child(1)
然后用这个值去定位,然后get参数即可:
现在有了videoid,那么lessonid在哪呢?
直接看右边的视频选择栏的代码,我们可以看到所有的lessonid都整整齐齐的写在这里:
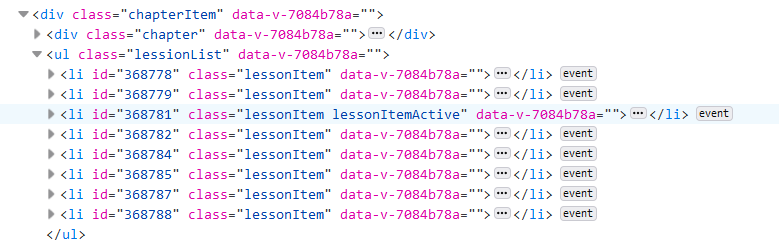

所以我们只需要遍历每一个class="lessonItem"的模块,获取lessonid后点击这个视频,再获取这个视频的videoid,这样最关键的两个id我们就都可以获得了:
这里需要注意的,是之一行和第四行的find *** 有略微的不同,之一行element后面还有一个s,这样可以抓取到到一个列表,否则是选择之一个
然后就可以直接构造post请求发送save2CCoursProgressV2包了
ps:save2CCoursProgressV2包的最后一个参数是毫秒级时间戳,但是time *** 获得的是秒级的时间戳,需要转化一下:
post请求(注意这里的url和之前的不一样,可以通过分析save2CCoursProgressV2包来获得):
这样就大功告成了!
0x04 最终代码
0x05 总结
这个程序写的还是比较简陋的,只支持了“兴趣课”,其他的课程由于网页格式不一样,应该是不适用的,而且courseId还需要手动看url来获得:
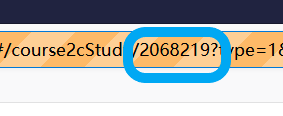
uuid也是通过查找save2CCoursProgressV2包获取的,不够智能化自动化,还需要好好打磨
若是学生选修了多门课程,那么在学生界面选择课程的语句也需要稍稍更改了,改成find_elements而不是find_element
不过这都是细节问题了,核心的登录、收集id信息、发送统计时长都做出来了,也亲测有效:

若是觉得效率不够,可以选择加多线程或者是Phantom *** 来提高效率~~
这次学习到了很多selenium的用法,也是受益匪浅
几点证明:
1.此步调只供进修交谈,请勿用来贸易用处
2.暂时只扶助“爱好课”的刷课,其余典型的课程还不扶助
3.步调尚不完备,然而道理沟通,触类旁通,欢送交谈
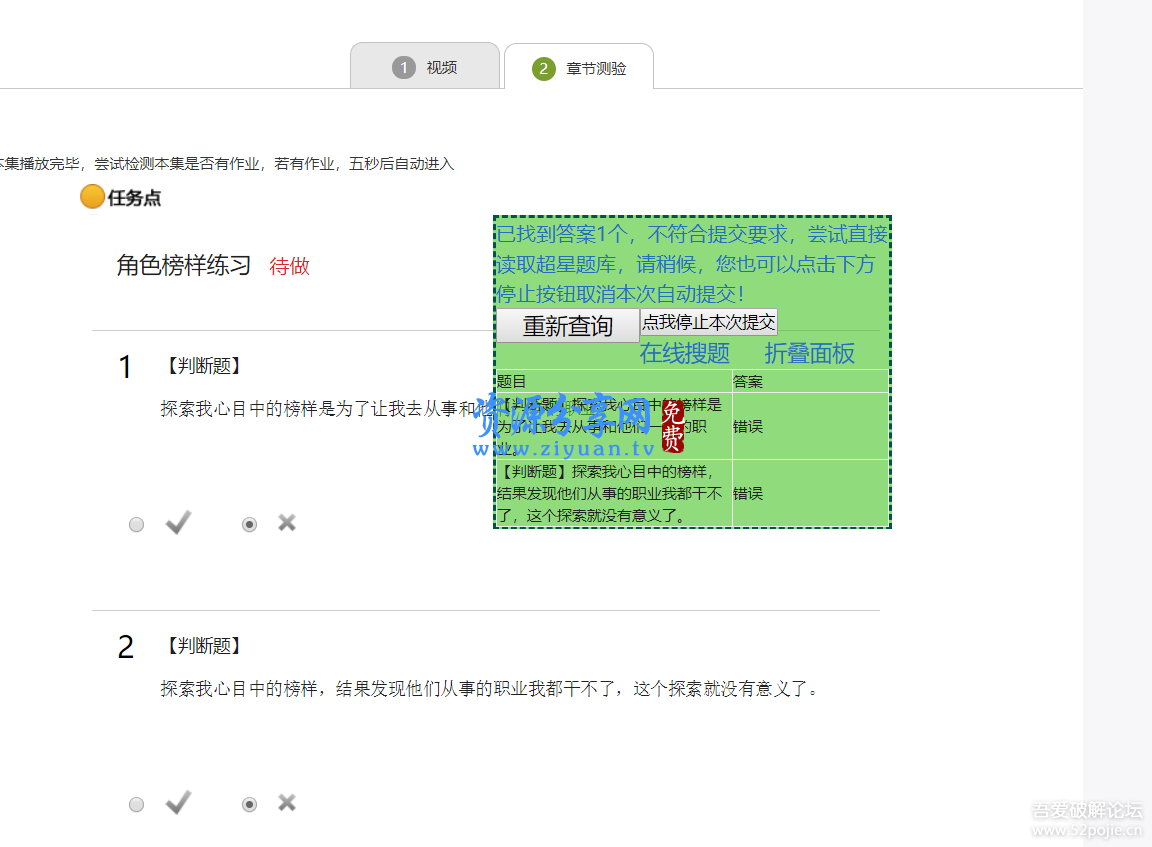
即使须要聪慧树网课刷课平台,这边不妨帮你:dao.cqrzr.com【功效纲要】
聪慧树刷课软硬件(wits lzss)最完备不会被质疑的刷课本领即是,模仿人看,
道理即是,你平常观察一节课(假如这节课15秒钟)。你须要观察 14.30-15秒钟,效劳器会计统计计。

这次是 2020-05-23 8:00 观察的这一节课。那么你观察下一节课 起码要在 8:14之后本领看到
(这是指看到。并不是看完),由于本软硬件是一次提交一节课,,反之则倡导大师 每隔30秒钟
提交一节课。固然你不妨径直树立功夫间隙(本软硬件以毫秒为单元),也不妨手动勾选。
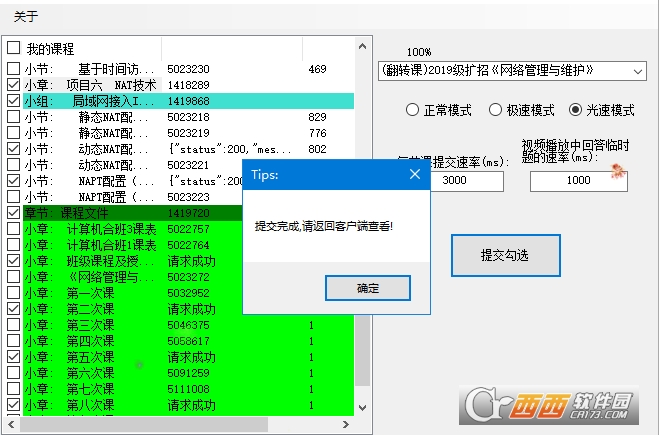
【中心功效】
聪慧树刷课软硬件(wits lzss)有三种刷课形式: 平常形式: 1倍速,望文生义和平常网页观察视频一律,
每节课提交3种数据。(安定) 极速形式: 可自设置倍速,引荐(1、2、5、10)每节课提交3种数据(安定),
若不是(1、2、5、10)则每节课提交1(变异数据)+2种数据。
(有危害) 光速形式: 径直设定几何秒一节课,每节课只提交2种数据。(慎用)
后盾挂尔雅欣赏器 (尔雅、超星和聪慧树等平台本子)功效纲要:1、机动播放下一集;2、翻开其余网页大概减少后不休憩;3、可机动跳过考证码;4、可多开页面挂机,同声看多个视频;5、扶助快进(慎用)、干脆进度(慎用),1.5 倍速率播放(慎用);7、多开账号请运用隐身窗口;8、功课考查一键答题。【怎样运用】1、解压载入的后盾挂尔雅欣赏器;2、在内里翻开 “chrome.exe” 文献,径直登录即可(左上方可采用书院);3、像平常一律看视频做功课,功课页面包车型的士精确谜底会机动选中;4、多帐号请运用兴建隐身窗口,赶快键 “ctrl+shift+n”。【扶助作家】【豁免责任证明】仅用来部分用处,切勿用来贸易用处,任何违规运用形成的法令制裁与自己无干,以上钩友谈话只 *** 其部分看法,不 *** 本网的看法或态度。【提醒消息】提醒:此免费版不扶助批量后盾挂,即使您是代看,请运用免开网页后盾效劳器的收款本子,免 cpu,免网速。【本子证明】暂时本子 v1.9
载入地方:https://www.liupan.net/file-809.html

超级好用的刷课插件~")
刷课加答题软件下载(支持限制时间)")


评论列表